Introduction
 Hello and welcome back!
Hello and welcome back!
Previously, we converted a Tensorflow FashionMNIST classification model from a 32-bit floating-point one into a quantized TFLite model for inferencing on EdgeAI processors. Also, we verified the model’s functionality, using a TFLite runtime interpreter. Now, we want to run our TFlite model on specialised machine learning hardware used, typically, to accelerate feed-forward Deep Neural Networks (DNNs).
This article, a brief interval in the basic classification series, specifically discusses the hardware delegate. In the first section I explain the role of the TensorFlow Lite hardware delegate. Then, I discuss the hardware compilation workflow for Coral EdgeTPU and TI’s TDA4VM DSP centric processors. Finally, I narrow the discussion down to compiling the TFLite Model, developed previously, to target Google’s Coral EdgeTPU. (N.B I’m still waiting for some pointers on compiling TFlite models for the Jacinto EVM and SK-TDA4VM Starter Kit. Once the method is fully understood, an upcoming article will walk through the compilation technique used for TDA4VM accelerators, too).
The TensorFlow Lite Hardware Delegate

Figure: Image taken from the Tensorflow article "Implementing a Custom Delegate".
A Tensorflow Lite delegate allows us to implement Machine Learning (ML) inferencing algorithms on custom accelerators like GPU’s, DSP’s and EdgeTPU’s. For example, TI’s TDA4VM family of processors, to accelerate inferencing on it’s C7x Digital Signal Processors (DSPs). To gain some understanding of the use and purpose of a hardware delegate let’s look at the definition, above, taken from Tensorflow.org.
Thus, it can be inferred from this definition that each implementation of a ML accelerator requires the implementation of a corresponding custom delegate. That is, a library that devolves a graph into the parts of inferencing that take place on the CPU and delegates the parts that are accelerated on the custom hardware, GPUs, TPUs or DSPs. I will not go into the details of how delegate libraries are developed in this article. However, in a future article we will develop a custom hardware delegate for a DNN, implemented in a Field Programmable Gate Array (FPGA).
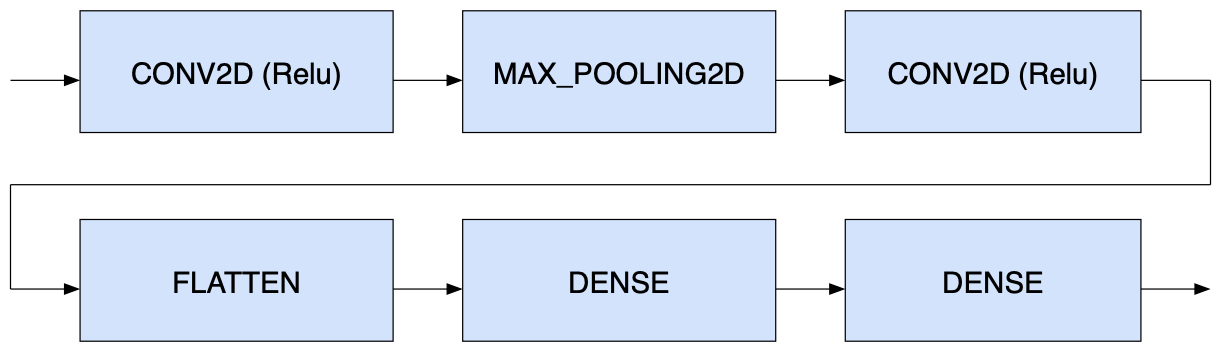
Figure: A graph of a typical Deep Neural Network (DNN).
Now, supposing we have a Tensorflow classification model implemented as the graph, shown above. Assume it has been converted into a TFLite model. Some or all parts of the graph may be delegated for acceleration. How does the TFLite runtime interpreter know the parts of the model to delegate to the accelerator?
Well, it is the job of a compiler to convert the TFLite model into a format that divides the model into non-accelerated and accelerated partitions. We will see how this is done for the Coral EdgeTPU in the next section.
(A demonstration of the compilation process will be carried out for the TDA4VM DSPs in an upcoming article. I have had a few issues in getting the TIDL compiler up and running and I am awaiting feedback from the TI forum on how to proceed).
Compilation for the Coral EdgeTPU
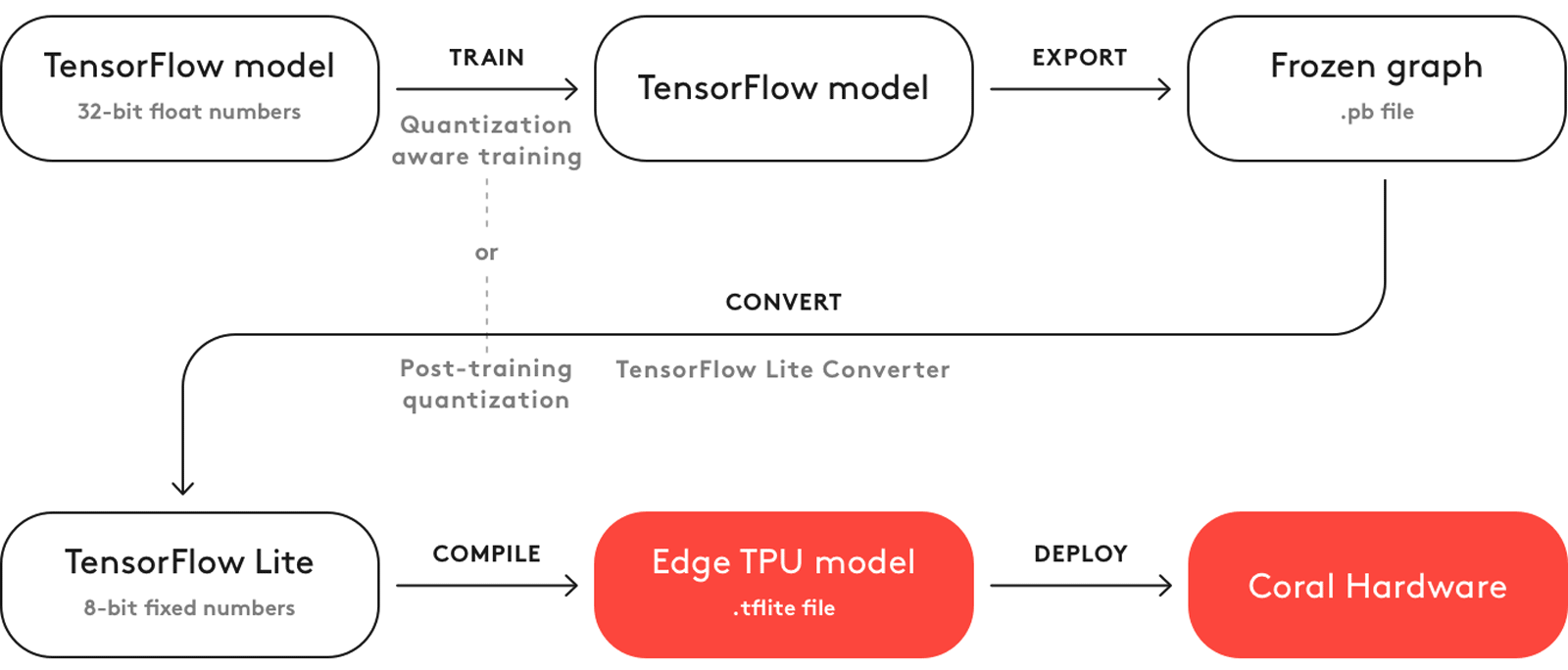
Figure: Image taken from the Coral article “TensorFlow Models on the Edge TPU”
In this section we are going to convert our frozen graph model, into a format suitable for our target delegate, the Coral EdgeTPU. We follow the workflow, shown in the Figure, above, by noting the following: In the first article we trained a basic classification model. However, this model will not make use of our EdgeTPU accelerator and since we cannot train a model with TensorFlow Lite we need to export and convert the model, using the design flow shown, above. We have already exported the model, in article 2, using the commands listed:
export_dir = 'saved_model/1'
tf.saved_model.save(model, export_dir)
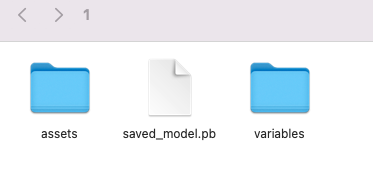
This saved our Tensorflow basic classification model, as the file and folders shown in the Figure, below. Where the frozen graph has been exported, as the file, saved_model.pb.
Then, we converted the model, using the following command (see details in article 2) and eventually saved the converted file, as model.tflite, as demonstrated by the following snippet of code:
# To quantize the model on export, set the optimizations flag to optimize for size.
converter = tf.lite.TFLiteConverter.from_saved_model(export_dir)
Also, in the second article, we confirmed the operation of our model in a TFlite runtime interpreter. We verified the operation of the model on TI’s Edge Cloud Tool, too, in the third article. From this point onwards things begin to become interesting, as we now need to compile our model, so that it can take advantage of the EdgeTPU (N.B A similar, but not identical, compilation process is carried out for the TDA4VM accelerator).
To commence the workflow, I tried to compile the TFLite model for the EdgeTPU on my Mac Mini M1 (Monterey 12). However, I couldn’t install pycoral~=2.0, since a candidate Python wheel has not yet been made available for MacOS Monterey 12. Thankfully, Google provides a web-based compiler through Google Colab web-based compiler using Google Colab. I grabbed the opportunity to use it, while thinking maybe their rivals should take note! The end result was that it produced the file, model_edgetpu.tflite with aplomb (See the Jupiter notebook, below). The model is now ready for inferencing on the Edge TPU. It’s as simple as that!
At this stage I have reached the conclusion that the Coral EdgeTPU compiler environment is slightly more advanced than TI’s EdgeAI compiler setup. Especially, since I have still not been able to compile a custom model for the TDA4VM.
"When your cup of happiness is full, someone always hits your elbow" - unknown.
However, my elation was soon nipped in the bud, as I realised that without the Python pycoral library installed I couldn’t test the compiled model in a Jupyter Notebook, on my Mac Mini M1. Although, I was able to install the EdgeTPU runtime I need to wait, until the Python wheel is updated for python 3.9-macos-monterey12. Unfazed, however, I have dusted off an old Raspberry Pi (RPi) 3 and inserted a Coral Accelerator USB Stick to test the implementation. I will do this once I have installed all the required tools on the RPi.
 |
 |
Figure: A TensorFlow Model can perform machine learning inferencing on a Coral USB Accelerator stick (left) or the Coral Dev Board Mini (right), once the model has been converted, exported and compiled, as a coral EdgeTPU delegate.
The implementation simply requires swapping the model.tflite for model_edgetpu.tflite in the Jupyter Notebook, developed in article 3. Although I will change course slightly and use a Coral Dev Board Mini, as it fits in nicely with a future series coming soon to this site. Also, once I overcome the stumbling block with the TI TIDL compiler tool, I’ll demonstrate inferencing on the TI EdgeAI Cloud Jacinto EVM, too!
Conclusion
Apart from one or two stumbling blocks I have finally managed to compile a TFLite model for use on EdgeAI hardware. We have just scratched the surface of using hardware delegates to accelerate feed-forward, deep neural networks for machine learning. Apart from the myriad of architectures and parameters that are available, as part of the model development process, we could consider transfer learning too. Hence, the Basic Classification series will be expanded to include image classification, feature extraction, object detection and semantic segmentation. All this, after article 4 of 4, which is coming soon!
Reference:
EdgeTPU compilation instructions: https://coral.ai/docs/edgetpu/compiler/#system-requirements
Google Colab EdgeTPU Compiler Jupyter Notebook
Copyright 2021 Google LLC¶
Licensed under the Apache License, Version 2.0 (the "License")
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
Compile a model for the Edge TPU¶
Simply upload a compatible .tflite file to this Colab session, run the code below, and then download the compiled model.
For more details about how to create a model that's compatible with the Edge TPU, see the documentation at coral.ai.
![]()

Upload a compatible TF Lite model¶
With a compatible model in-hand, you can upload it as follows:
- Click the Files tab (the folder icon) in the left panel. (Do not change directories.)
- Click Upload to session storage (the file icon).
-
Follow your system UI to select and open your
.tflitefile.When it's uploaded, you should see the file appear in the left panel.
- Replace
example.tflitewith your uploaded model's filename:
%env TFLITE_FILE=model.tflite
- Now click Runtime > Run all in the Colab toolbar.
Get the Edge TPU Compiler¶
! curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
! echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list
! sudo apt-get update
! sudo apt-get install edgetpu-compiler
Compile the model¶
! edgetpu_compiler $TFLITE_FILE
The compiled model uses the same filename but with "_edgetpu" appended at the end.
If the compilation failed, check the Files panel on the left for the .log file that contains more details. (You might need to click the Refresh button to see the new files.)
Download the model¶
import os
from google.colab import files
name = os.path.splitext(os.environ['TFLITE_FILE'])[0]
files.download(str(name + '_edgetpu.tflite'))
If you get a "Failed to fetch" error here, it's probably because the files weren't done saving. So just wait a moment and try again.
Run the model on the Edge TPU¶
Check out some examples for running inference at coral.ai/examples.